본 내용은 참고 자료에 있는 블로그가 내용이 너무 좋아서, 해당 블로그 내용을 바탕으로 번역하면서 작성하였음을 밝힙니다.
Paper
- Attention is all you need
https://arxiv.org/pdf/1706.03762.pdf
Vocab size
- 단어장 크기는 unique word의 수로 결정된다.
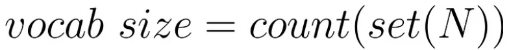
- N을 구하기 위해서 단어를 하나하나 토큰화해야 한다.
Encoding
- unique word에 고유의 index 수를 할당해야 한다.
- 결과
- Word to index
- index to wor
Calculating Embedding

- 한 문장을 이루는 토큰이 input sequence로 들어갔다고 한다면, 토큰을 벡터로 embedding 해야 한다.
- 논문에서는 각 토큰 당 512 dimenstional embedding vector를 사용했다.

- embedding vector 값은 0 과 1 사이의 값으로 구성되어 있고 처음에 랜덤한 값으로 채워진다.
- 이후에 모델이 학습하기 시작하면서 업데이트 된다. 그리고 트랜스포머 모델은 각 단어들 사이에 문맥을 이해하기 시작한다.
Caculating positional Embedding
- embedding matrix가 만들어지고 나서는 positional Embedding을 계산해야 한다.
- fomulas
- 각 위치에 따라 두 가지 공식으로 계산된다.

- 단어의 주기성을 주기 위함으로 바꿔서 해도 상관 차이가 많이 없었다.
- 문장에서 가장 첫 번째 토큰에 해당하는 단어의 positional embedding을 계산한다.
- 예시는 다음과 같다
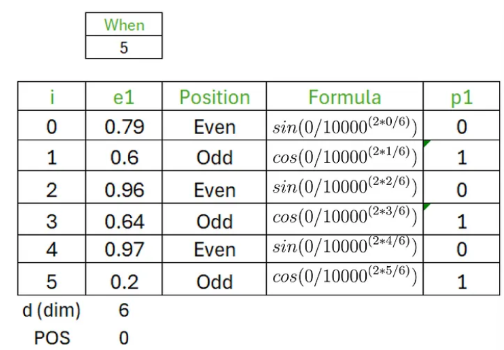
- 이러한 과정을 모든 단어에 적용한다.

Concatenating Positional and Word Embeddings
지금까지 Positional embedding과 Word Embedding을 구했다. 이후에는 word Embedding + Positional embedding을 한 matrix를 구해준다.

Multi Head Attention
- mutil head attention은 많은 단일 head attention으로 구성되어 있다.
- 단일 attention 얼마나 결합할지는 우리가 결정하게 된다.
- LLaMA의 경우 32 single head를 사용한다
Single head Attention
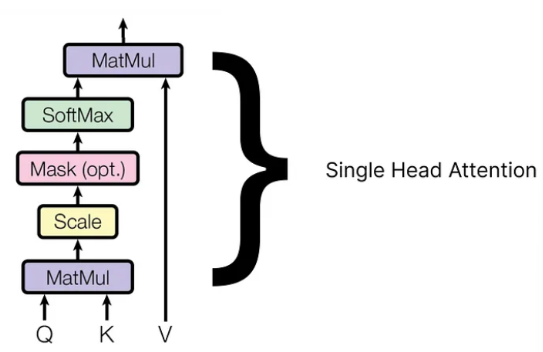
단일 head attention은 query, key, value로 구성되어 있고, 각 값에 weight가 다른 matrix가 곱해져서 각각 고유한 상태가 있는 상태가 된다.
key, Query,value는 이전에 계산했던 임베딩 행렬의 transpose에 각각 곱해진다.
- Query
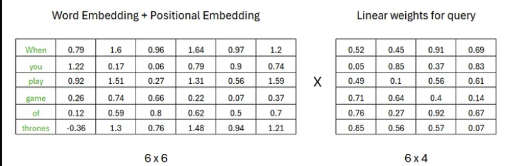
- key
- Value
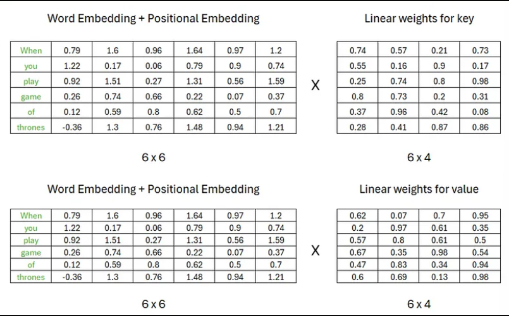
결과적으로 세가지 구성 값들은 모두 동일한 형상을 갖는다.
세가지 서로 다른 가중치를 갖는 Query key value matrix를 구한 후에 각 single head attention에서 계산된다.

- Query와 key의 transpose 행렬을 곱해서 정방 행렬을 구성해 준다.
- 구하려는 target Query에 대해서 input 문장에 있는 모든 단어에 대해서 얼마나 mapping이 되는지가 표현된 matrix가 되는 것 같다.
- key와 Query를 구하고 나서 결과 matrix를 scaling 해주기 위해서 차원 크기의 제곱근 만큼 나눠준다.

- 다음 층에서 구성되어 있는 masking은 option이다.
- transformer 모델에서는 decoder에서 masking을 계산해준다.
- masking은 앞으로 나올 단어들을 masking 처리함으로써 단계적으로 나올 단어를 유추할 수 있도록 돕는다. 마스킹 처리를 해주지 않으면 생성하기도 전에 cheating하는 것과 같은 개념이 된다.
- scaling을 해준 이후에 softmax 함수를 적용해서 각 토큰에 대한 확률값 이 출력된다.
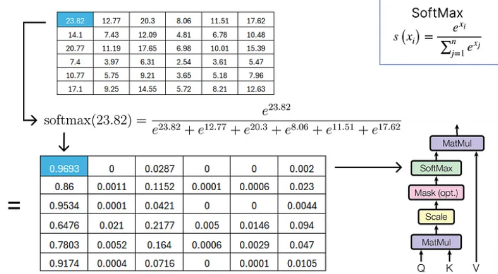
- 소프트맥스를 적용한 정방 행렬에 value 값을 곱해준다.
- Value값을 곱해줌으로써 원본 값에 각 토큰의 대한 확률 값이 내적되면서 Query에 해당하는 부분이 Attention된 결과 값이 나오게 된다.
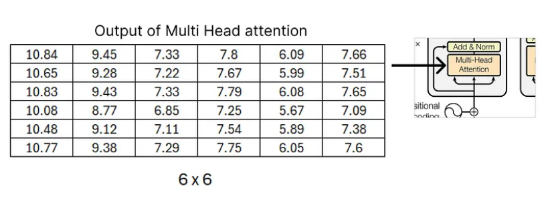
- 여기까지가 Single head attention의 결과 값이다.

Multi head attention
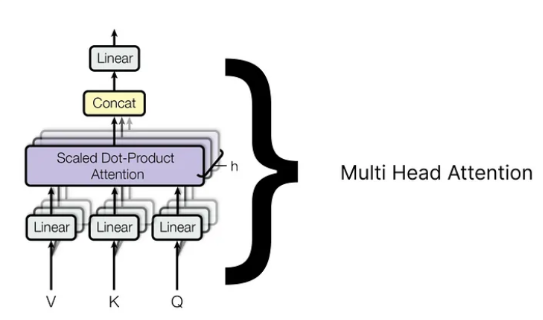
- multi head attention은 일단 모든 single attention 각각 모두 output을 만들고, 해당 output들이 모두 concatenate 된다.
- 최종적으로 concatenated 한 matrix도 랜덤 값으로 초기화한 가중치 행렬을 곱해서 다시 선형 변환을 하게 된다.
- 여기서 가중치 행렬은 이후에 훈련되면서 업데이트 된다.
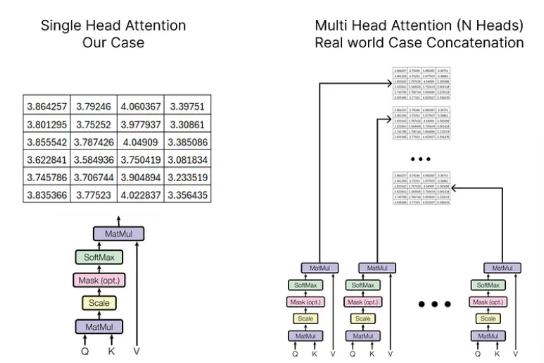
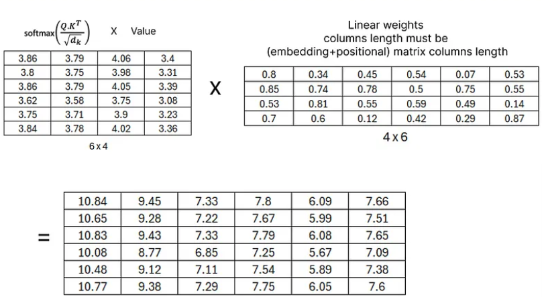
- 여기서 곱해주는 선형 가중치 열의 길이는 반드시 이전에 계산했던 임베딩 행렬 열의 크기와 같아야 한다.
- 그 이유는 최종 결과로 나온 값에 결과적으로 나온 normalized matrix를 더해줄 것이기 때문이다.
Adding and Normalizing
Adding
- Output of Multi head Attention + Embedding matrix
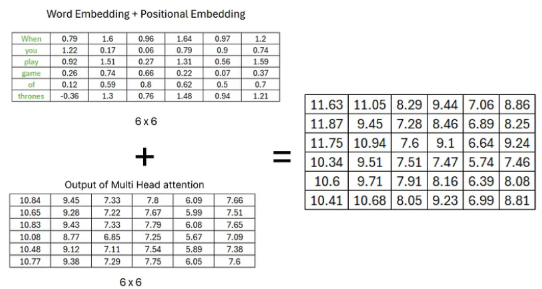
- 원본 값을 더해주는 residual을 add 해주는 과정으로 보인다.
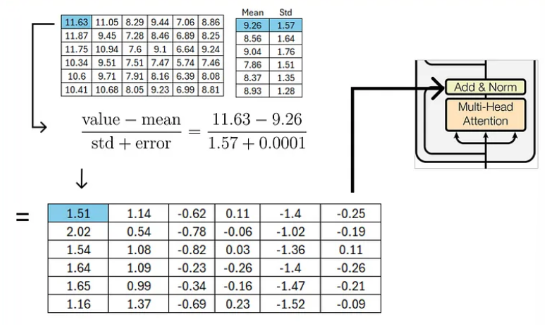
Normalize
- 정규화 해주기 위해서 우리는 행방향으로 평균과 표준편차를 계산해준다.

- 정규화해주는 과정에서 std를 나눠주게 되는데 여기에 아주 작은 error값을 추가해준다.
- 그 이유는 zero값으로 division을 하지 않기 위함이다.
Feed Forward Network
- 정규화를 마친 후에 정방향 네트워크 과정을 거친다.
- 단순한 선형 layer와 activation으로 relu를 사용한다.

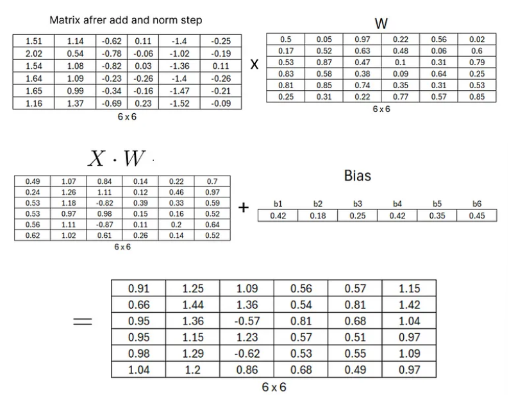

Adding and Normalizing Again
- 정방향 네트워크도 거친 후에 잔차 연결을 해주고 Normalizing을 해준다.
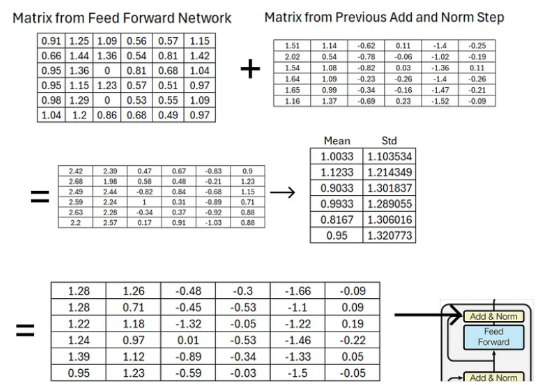
- 이전에 거쳤던 add, norm block에서 나온 output을 더해준다.
- 최종 output matrix는 이후에 decoder part에서 query key matrix로 제공될 것이다.
디코더는 추후에 포스팅해보도록 하겠습니다.
Rerference
2024.01.15 - [AI] - Train Once, Test Anywhere : Zero-Shot Learning for Text Classification
Train Once, Test Anywhere : Zero-Shot Learning for Text Classification
지도학습과 비지도 학습 등 최근에는 다양한 인공지능 학습 방법에 대한 연구가 이뤄지고 있다. 그중에서도 Zero shot learning이라는 학습 방법에 대해 궁금해서 관련 논문으로 개념을 알아보려 한
love-eating.tistory.com
2024.01.15 - [전체] - EDA를 왜 해야 할까?
2024.01.15 - [AI] - 분류 모델의 종류(classification model)
분류 모델의 종류(classification model)
로지스틱 회귀 (Logistic Regression) 개념: 선형 결정 경계를 통해 이진 분류를 수행하는 모델. 목적: 데이터의 특성을 학습하여 새로운 데이터를 분류. 원리: 선형 결정 경계를 찾아내기 위해 최적의
love-eating.tistory.com
'AI' 카테고리의 다른 글
| Seq2Seq(시퀀스 투 시퀀스) (0) | 2024.01.15 |
|---|---|
| EDA를 왜 해야 할까? (0) | 2024.01.15 |
| 머신러닝 요약(ML Summary) (0) | 2024.01.15 |
| 분류 모델의 종류(classification model) (0) | 2024.01.15 |
| Train Once, Test Anywhere : Zero-Shot Learning for Text Classification (0) | 2024.01.15 |



