- Seq2Seq 모델은 번역, 요약과 같이 시퀸스(sequence) Seq2Seq 모델은 번역, 요약과 같이 시퀸스(sequence)
- RNN 기반 모델
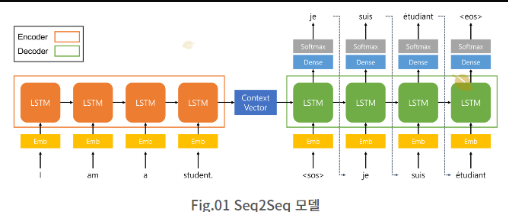
- '시퀸스를 받아들이는 부분'과 '시퀸스를 출력하는 부분'을 분리한다
- 기계 번역, 챗봇, 요약, 질의응답 등의 작업에서 널리 사용한다.
Language Model
- 단어의 시퀀스를 보고 다음 단어에 확률을 할당한다
- n-1개의 단어 시퀀스 W1,⋯ ,Wn−1w1,⋯,wn−1가 주어졌을 때, n번째 단어 wn 으로 무엇이 올지를 예측하는 확률 모델이다.

Statstic Language Model
- 단어 시퀀스에 대한 확률분포(probability distribution)이다
- context-dependent 성격 - 학습 데이터에 민감하다
이점
- 언어모델의 불확실성(uncertainties)을 가진 존재를 정량화할 수 있다.
- 확률분포를 가지고 단어의 시퀀스를 뽑을 수(sample) 있다. 즉 텍스트 생성이 가능하다.
유니그램 언어 모델
- 단어가 서로 독립(independent)이라고 가정한다
- 단어 시퀀스의 등장확률이 각 단어 발생확률의 곱으로 정의한다.
- 각 단어의 등장 순서가 바뀌어도 개별 단어 확률의 곱은 변하지 않는다
- 유니그램 모델 table
- 학습말뭉치에 등장한 각 단어 빈도를 세어서 전체 단어수로 나누어준 것이다.
- 총합 1
- 예시

- 즉 등장 빈도가 높은 단어일 수록 출현 확률이 높아진다
- 그래서 말뭉치가 달라지면 그 확률 값이 확 달라진다 Context dependent
- 위의 예시에서 최대 우도 추정량

the maximum likelihood estimator
- 문제는 우리에게 주어진 데이터(말뭉치)가 모집단 전체를 포괄하는 게 아니라 일부라는 점이다.
- 잠재 공간 세타가 주어졌을 때 관측치가 나타날 확률을 최대홀 만드는 모수를 선택한다.
- 빈도 수만을 가지고 하는 것이 아니라 분포 자체에서 샘플링되었고 가정하고 추정한다.
- 결과를 보고 원인을 추정하는 방법이다.
한계
- 학습말뭉치에 존재하지 않는 단어의 경우 그 확률이 0이다.
- 학습말뭉치에 의존적이다.
- 아울러 조사, 어미 등 기능적 단어(functional words, 영어의 경우 관사 등)가 우리가 관심이 있는 주제 단어(topic words)보다 훨씬 빈도가 높아 원하는 결과를 내기가 쉽지 않을 수 있다.
신경망 언어 모델
- 통계적 언어 모델의 한계점으로 등장한 신경망 언어 모델이다.
- 지금의 Embedding 레이어의 아이디어인 모델이다.
- 신경망 언어 모델의 시초인 피드 포워드 신경망 언어 모델(Feed Forward Neural Network Language Model)
- 기존 n-gram 모델의 한계
- 언어 모델은 충분한 데이터를 관측하지 못하면 언어를 정확히 모델링하지 못하는 희소 문제(sparsity problem)가 있다.
- 희소 문제 해결방안
- 단어의 의미적 유사성을 알수 있다면 해결할 수 있는 문제이다.
- 단어 간의 의미적 유사성을 학습해야 한다.
- 워드 임베딩(word embedding)
- n개까지 밖에 고려하지 못한다.

NNLM
- 희소문제로 제안된 모델이다.
- 희소 문제란, 모델이 충분한 데이터를 관측하지 못하면 언어를 정확히 모델링 할 수 없는 문제이다.
- 언어 모델은 주어진 단어 시퀀스로부터 다음 단어를 예측한다.
- n-gram 언어 모델처럼 다음 단어를 예측할 때, 앞의 모든 단어를 참고하는 것이 아니라 정해진 개수의 단어만을 참고한다.
- 윈도우 사이즈만큼의 단어만을 참고하여 예측한다
과정

- 투사층의 크기를 M
- 투사층에서 V × M 크기의 가중치 행렬과 곱

- 룩업 테이블이 투사층에서 출력으로 나온다
- 룩업 테이블 후에는 V차원을 가지는 원-핫 벡터는 이보다 더 차원이 작은 M차원의 벡터로 맵핑된다.
- 벡터들은 초기에는 랜덤한 값을 가지지만 학습 과정에서 값이 계속 변경된다.
- 각 단어가 테이블 룩업을 통해 임베딩 벡터로 변경되고, 투사층에서 모든 임베딩 벡터들의 값은 연결된다.(concatenate)

- 활성화 층을 가지지 않는 선형층이다
- 투사층의 결과는 h의 크기를 가지는 은닉층을 지납니다
- 여기서 은닉층은 활성화함수를 가지는 비선형 층이다.

- 최종 출력은 소프트맥스(softmax) 함수 0과 1사이의 실수값을 가지며 총 합은 1이 되는 상태로 j번째 단어가 다음 단어일 확률이다 실제 정답에 해당되는 단어인 원-핫 벡터의 값에 가까워져야 한다
- NNLM는 손실 함수로 크로스 엔트로피(cross-entropy) 함수를 사용한다.
- 다중 클래스 분류 문제이다.
- 역전파가 이루어지면 모든 가중치 행렬들이 학습된다.
- 이때, 투사층에서의 가중치 행렬도 포함되므로 임베딩 벡터값 또한 학습된다.
이점과 한계
- 단어의 유사도를 계산해서 희소 문제(sparsity problem)를 해결한다.
- 고정된 길이 입력, n개만을 참고하여 단어를 예측할 수 있다
- 즉 아무리 시퀀스가 길어도 n개만을 참고해서 단어를 예측하게 된다.
- 해결 방안
- 순환 신경망(Recurrent Neural Network, 이하 RNN)을 활용한 언어 모델이다.
RNN
- 여러 개의 단어(Embedding)를 합쳐(Concatenate) 고정된 크기의 Weight를 Linear로 처리하는 방식의 한다
- 고정된 크기의 W가 선언되지만 입력을 순차적으로 적립한다
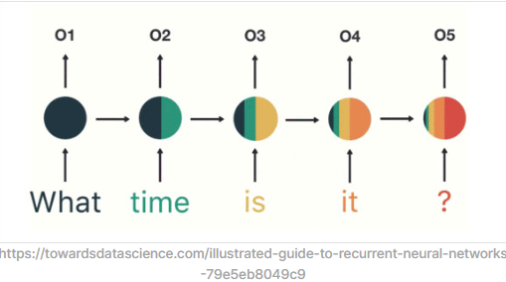
한계
- 기울기 소실이 된다.
- LSTM이 제안되었지만 여전히 기울기 소실문제 존재한다.
- 번역 task 불가하다.
- 어순이 다른 경우 순차적으로 처리하는 RNN은 task 처리가 불가하다.
- 번역은 모든 text sequence를 읽고 문장을 생성해내는 task가 필요하다고 하여 Sequence to Sequence(Seq2Seq) 구조를 제안되었다.
Sequence to Sequence
Introduction
- DNN의 한계
- DNN은 유연하고 강력함에도 불구하고, input과 target이 고정된 dimension의 vector인 경우의 문제에만 사용
- 문제
- input과 target이 길이에 대한 정보가 미리 주어지지 않은 sequence
이에 LSTM을 활용해서 sequence에서 sequence로 가는 구조를 소개한다.

전략
- input sequence를 RNN을 통해 고정된 길이의 vector로 만든 후에 다시 그 vector를 RNN을 통해 우리가 원하는 target sequence를 구하는 방법
- 하지만 RNN은 장 단기 기억의 한계가 있기 때문에 Long Short-Term Memory(LSTM)을 사용한다.
The Model
input sequence에 대한 output sequence의 조건부 확률 p(y1,...,yT′|x1,...,xT)를 구하는 것이다.
- 위의 전략대로 우선 주어진 input sequence를 통해 고정된 길이의 vector representation v를 구한다
- v는 첫 RNN의 마지막 hidden state의 값
- LSTM을 통해 y1,...,yT′′에 대한 확률을 게산

- 과정
- 오른쪽 항은 전체 vocabulary의 단어를 통해 softmax값을 계산해서 구한다
- 문장이 끝났다는 정보를 주고 그 지점부터 다시 output의 계산을 시작한다
- 첫 번째 시도
- input sequence와 output sequence에 대해 두개의 다른 LSTMs를 사용했다
- 두 번째 시도
- 두 번째로는 deep한 LSTM의 성능이 더 뛰어난 것을 확인한 후 4개의 layer를 사용하는 LSTM을 사용했다
- 세번째 시도
- input sequence의 순서를 뒤집어서 사용한다.
- a, b, c를 d, e, f로 번역하는 대신 순서를 바꿔 c, b, a 를 LSTM을 통해 d, e, f 값이 나오도록 학습한다.
- 간단한 data transformation이 LSTM의 성능을 획기적으로 올려준다는 것을 확인한다.
Experiment
DATA
- 총 12M개의 sentence 중 일부
- 348M개의 프랑스어 단어와 304M개의 영어 단어
- 160,000개의 가장 많이 사용되는 단어
- vocabulary에 포함되지 않은 단어는 “UNK”
학습
- 깊은 LSTM 모델을 많은 문장 쌍으로 학습시키는 것
- 주어진 문장 S에 대한 정확히 번역된 문장 T의 log-확률값을 최대화 하는 것
- 가장 높은 확률을 문장 T를 찾는다
예측
- 예측 과정에서는 간단한 left-to-right beam search decoder
- B개의 문장을 정하고 각 timestep마다 다른 문장들을 추가한 후 위의 log-확률이 높은 B개를 제외하고 나머지는 모두 버린다.
결과
- LSTM에서 source sentence를 거꾸로 사용했을 때 더욱 좋은 결과가 나왔다.
- perplexity는 5.8에서 4.7까지 떨어졌고, BLEU score는 25.9에서 30.6까지 올랐다.
- 단어끼리의 평균 길이는 변하지 않고 처음의 단어에 대해 대응되는 단어와 거리가 가까워지기 때문에 조금 더 효율이 올라갔을거라는 추측
Training detail
- 4개의 layer
- 1000개의 cell
- 단어 embedding 1000 dimenstion
- 160,000개의 input vocabulary
- 80,000개의 output vocabulary
- 모든 파라미터는 (-0.08, 0.08)사이
- SGD 사용, learning rate = 0.7, 5에폭 후에는 0.5에폭마다 learning rate를 절반으로 줄임. 총 7.5에폭으로 학습
- 128 sequence 크기의 배치 사용
- Vanishing gradient는 발생하지 않았지만, exploding gradient의 발생 떄문에 gradient의 norm 값에 대해 constraint
- 짧은 문장이 대부분이고 , 긴 문장 몇 개가 포함되어 있다. 따라서 미니 배치로 학습 시 길이가 너무 달라 학습이 잘되지 않는 문제를 위해 미니 배치 안에서 길이를 고정
Encoder
- 시퀸스를 받아들이는 부분
- n개의 단어 동시에 나타날 확률
Inference
- 인코더의 은닉 상태를 적절한 값(ex. 영벡터)으로 초기화한다.
- 매 시점(time step) 원문의 단어(token)가 입력되면(정확히는, 단어의 임베딩이 입력되면) 인코더는 이를 이용해 은닉 상태를 업데이트한다.
- 입력 시퀸스의 끝까지 이 과정을 반복하면 인코더의 최종 은닉 상태는 입력 시퀸스의 정보를 압축 요약한 정보가 된다.
- 마지막 시점에서의 인코더 은닉 상태를 컨텍스트 벡터라 하고, 이 값은 디코더로 넘어간다.
Decoder
- 시퀸스를 출력하는 부분
- 고정된 크기의 벡터로 변환
- 결과물을 생성해야 하므로 Fully Connected 레이어가 추가
- 출력값을 확률로 변환해 주는 Softmax 함수도 추가
- 매 스텝 생성하는 출력은 우리가 원하는 번역 결과에 해당하므로 LSTM 레이어의
return_sequences변수를True로 설정하여 State 값이 아닌 Sequence 값을 출력
Inference
- 전달받은 컨텍스트 벡터로 자신의 은닉 상태를 초기화
- 매 시점 자신이 바로 직전 시점에 출력했던 단어를 입력으로 받아, 자신의 은닉 상태를 업데이트
- 이를 이용해 다음 단어를 예측한다(최초 시점에서는 시퀸스 시작을 의미하는
<sos>토큰(start of sequence)을 입력으로 받는다). - 시퀸스 끝을 나타내는
<eos>토큰(end of sequence)이 나올 때까지 수행
Result

Seq2Seq 모델의 학습 방법 - 교사 강요(teacher forcing)
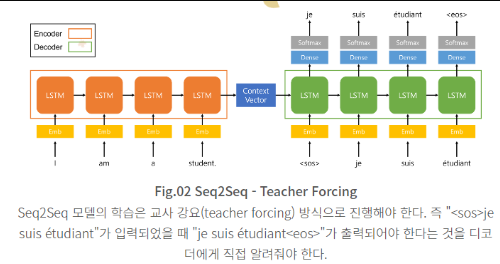
- 이전 시점의 디코더 출력 단어를 다시 디코더 입력값으로 사용하는 방식으로는 디코더가 잘 학습되지 않는다
- 디코더의 입력 값으로 이전 시점의 디코더 출력 단어가 아닌 실제 정답 단어를 입력해 줘야 한다. 이 방식을 교사 강요(teacher forcing)라고 한다.
한계
- 입력 시퀸스의 모든 정보를 하나의 고정된 크기의 벡터(Context Vector)에 다 압축 요약하려 하다 보니 정보의 손실이 생길 수밖에 없다. 특히 시퀸스의 길이가 길다면 정보의 손실이 더 커진다.
- RNN 구조로 만들어진 모델이다 보니, 필연적으로 gradient vaninshing/exploding 현상이 발생한다.
Reference
- https://heekangpark.github.io/nlp/attention
- https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/09/16/LM/
- https://hyen4110.tistory.com/32
- https://hyen4110.tistory.com/31
- https://heekangpark.github.io/nlp/attention
어텐션 메커니즘 (Attention Mechanism) : Seq2Seq 모델에서 Transformer 모델로 가기까지
Reinventing the Wheel
heekangpark.github.io
2024.01.15 - [AI] - Transformer - Encoder(어텐션 메커니즘)
Transformer - Encoder(어텐션 메커니즘)
본 내용은 참고 자료에 있는 블로그가 내용이 너무 좋아서, 해당 블로그 내용을 바탕으로 번역하면서 작성하였음을 밝힙니다. Paper Attention is all you need https://arxiv.org/pdf/1706.03762.pdf Vocab size 단어
love-eating.tistory.com
2024.01.15 - [AI] - Train Once, Test Anywhere : Zero-Shot Learning for Text Classification
Train Once, Test Anywhere : Zero-Shot Learning for Text Classification
지도학습과 비지도 학습 등 최근에는 다양한 인공지능 학습 방법에 대한 연구가 이뤄지고 있다. 그중에서도 Zero shot learning이라는 학습 방법에 대해 궁금해서 관련 논문으로 개념을 알아보려 한
love-eating.tistory.com
'AI' 카테고리의 다른 글
| Recurrent Neural Network (0) | 2024.01.20 |
|---|---|
| A Review of Generalized Zero-Shot Learning Methods (0) | 2024.01.16 |
| EDA를 왜 해야 할까? (0) | 2024.01.15 |
| Transformer - Encoder(어텐션 메커니즘) (0) | 2024.01.15 |
| 머신러닝 요약(ML Summary) (0) | 2024.01.15 |


