머신러닝 알고리즘 종류
- 지도 학습 (Supervised Learning)
- 비지도 학습(Unsupervised Learning)
- 강화 학습 (Reinforcement Learning)
지도 학습
지도 학습은 사례들을 기반으로 예측을 수행한다. 이미 분류된 학습용 데이터를 가지고 훈련을 하고, 학습용 데이터를 바탕으로 일반화된 모델을 가지고 새로운 사례를 예측한다.
- Classification
- binary classification
- multi-class classification
- Regression
- 연속 값 예측
- Forecasting
- 과거 및 현재 데이터를 기반으로 미래 예측
준지도 학습
지도 학습은 데이터 분류 작업에 비용과 시간이 많이 든다. 따라서 미분류 사례와 함께 소량의 분류 데이터를 사용한다.
비지도 학습
비지도 학습은 분류되지 않은 데이터를 가지고 학습한다. 분류되지 않은 데이터라는 것은 아직 ‘어떤 것’인지 모르는 상태를 말한다. ‘어떤 것’이 가지는 고유한 패턴을 발견하는 방식으로 학습이 진행된다
- Clustering
- 고유한 패턴을 바탕으로 여러 그룹으로 분류
- Dimension Reduction
- 차원 축소
강화 학습
강화학습은 환경을 관찰해서 학습 주체가 스스로 행동하게 하는 모델이다
- Agent
- 학습 주체
- Environment
- Agent에게 주어진 환경
- Action
- 환경으로부터 주어진 정보를 바탕으로 Agent가 판단하는 행동
- Reward
- 행동에 대한 보상을 머신러닝 엔지니어가 설계
- 대표적인 알고리즘
- Monte Carlo Methods
- Q-learning
- Policy Gradient Methods
알고리즘 선택
- 고려 사항
- 정확성
- 학습 시간
- 사용자 편의
Scikit - Learn
- 공식 홈페이지
- scikit-learn: machine learning in Python — scikit-learn 1.3.2 documentation
- API reference
- API Reference
- 유래
- Scipy + Toolkit
- Task
API Reference
This is the class and function reference of scikit-learn. Please refer to the full user guide for further details, as the class and function raw specifications may not be enough to give full guidel...
scikit-learn.org
scikit-learn: machine learning in Python — scikit-learn 1.4.0 documentation
Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross validation, metrics, and more...
scikit-learn.org
- classification
- Regression
- Clustering
- Dimensionality Reduction
- Preprocessing
- 주요 모듈
- Estimator
- 데이터 셋을 기반으로 머신러닝 모델의 파라미터를 추정하는 객체
- 모든 머신러닝 모델은 Estimator라는 파이썬 클래스
- 인터페이스 역할을 하는 클래스라고 생각하면 될 것 같다..
- 각 모델들이 Estimator class를 상속 받아 사용하는 것으로 보인다.
- 주요 method
- fit
- predict
- Estimator
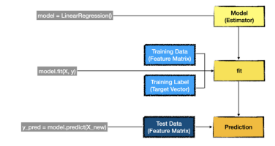
데이터 표현법
- 데이터 표현 방식
- Feature Matrix
- 입력 데이터
- 열
- 표본
- Target Vector
- 정답 데이터
- 특성 행렬로부터 예측하려 하는 값
- 보통 1타원 벡터(반드시 아님)
- Feature Matrix
- !https://d3s0tskafalll9.cloudfront.net/media/images/Untitled_1.max-800x600.png
- 간단한 예제
- Scikit learn API
- Model (Data → Model → 수익)
- ETL
- Categorical expansion
- Null imputation
- Feature Scaling
- → transformer 를 통해 ETL 과정을 거친다
- Train
- fit
- Validate
- Predict
- ETL
- Model (Data → Model → 수익)
- classification 실습
- 과정
- 데이터
- X ,y data를 가지고 데이터를 나눈다
- 데이터를 전처리 가공 하는 과정을 거친다
- 모델
- 모델을 선정한다
- 모델을 구조를 만든다
- 모델을 compile 한다
- 훈련
- X, y 데이터를 가지고 모델을 훈련한다
- 예측
- test data를 가지고 모델을 예측한다
- 평가
- Accuracy score
- Confusion metrics
- Loss값
- 데이터
- 마무리하며..
- 어떤 데이터를 사용할 것인가?
- 어떻게 데이터를 정제 전처리할 것인가?
- 어떻게 독립적인 feature를 선정할 것인가?
- 어떤 모델이 있는가?
- 어떤 모델이 적합한가?
- 모델은 어떻게 구성되어 있는가?
- 훈련 시간은 얼마나 걸리나?
- 시간 대비 효율은 어떤가?
- 예측 결과는 어떤가?
- 어떤 평가 지표가 적절한가?
- 과정
- Scikit learn API
Reference
https://blogs.sas.com/content/saskorea/2017/08/22/최적의-머신러닝-알고리즘을-고르기-위한-치트/
https://jakevdp.github.io/PythonDataScienceHandbook/06.00-figure-code.html#Features-and-Labels-Grid
'AI' 카테고리의 다른 글
| Chatbot - 검색 기반 모델? 생성 모델? (0) | 2024.01.23 |
|---|---|
| 번역의 흐름 (0) | 2024.01.22 |
| Recurrent Neural Network (0) | 2024.01.20 |
| A Review of Generalized Zero-Shot Learning Methods (0) | 2024.01.16 |
| Seq2Seq(시퀀스 투 시퀀스) (0) | 2024.01.15 |


{kind=link}