규칙 기반 기계 번역(RBMT, Rule-Based Machine Translation)
경우의 수를 직접 정의해주는 방식입니다. 수많은 규칙들은 모두 언어학을 기반으로 합니다.
- 한계
- 규칙에 없는 문장이 들어올 경우 번역이 불가능합니다.
- 유연성이 떨어지며, 무엇보다 모든 규칙을 정의하는 과정이 복잡하고 오랜 시간이 필요합니다.
위의 기계 번역은 한계가 존재하고 더 유연하게 번역해낼 수 있는 방법이 필요했습니다. 그래서 IBM에서 1988년에 통계적 기계 번역을 선보입니다.
통계적 기계 번역
수많은 데이터로부터 통계적 확률을 구해 번역을 진행합니다. 통계적 언어 모델을 기반으로 동작합니다.
조건부 확률
- 조건부 확률은 아래와 같은 관계를 갖습니다.
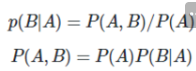
- 4개의 확률이 조건부 확률의 관계를 가진다고 가정했을 때 아래와 같이 표현합니다.

- 이를 조건부 확률의 연쇄 법칙이라고 하고 4개가 아닌 n개에 대해서 일반화를 했을 때 아래와 같습니다.

카운트 기반의 접근
통계적 기계 번역에서 문장의 확률을 구할 때 이전에 나온 확률 값에 다음 단어가 나올 확률을 곱해서 구합니다. 그렇다면 다음 단어에 대한 확률을 어떻게 구할 수 있을까?
예를 들어서 다음과 같습니다.

- 장점
- 개발에 대한 비용이 훨씬 적습니다
- 많은 데이터가 있다면 유연한 문장 생성이 가능합니다
- 한계
- 희소 문제 (Sparsity Problem)언어 모델의 목표 자체가 기계에 많은 코퍼스를 훈련시켜서 언어모델을 통해서 현실 세계의 확률 분포를 근사하는 것입니다. 그래서 카운트 기반의 접근은 정말 방대한 양의 데이터가 필요합니다.
- 예를 들면 코퍼스에 존재하지 않는 word 라고 한다면 카운트 기반이기 때문에 확률이 0이 됩니다. 그렇다면 해당 모델은 언어를 정확히 모델링 하지 못하는 문제가 발생합니다. 이와 같이 충분한 데이터를 관측하지 못해서 정확히 언어를 모델링하지 못하는 문제를 희소 문제라고 합니다.
- 언어 모델은 실생활에서 사용되는 언어의 확률 분포를 근사시켜서 모델링 합니다. 정확하게 알 수는 없지만 현실에서도 어떤 word가 나올 확률이라는 것이 존재합니다. 실제 자연어의 확률 분포 , 현실에서의 확률 분포라고 명칭합니다.
동작 방법
통계적 언어 모델을 활용해서 번역기 만들기 위해서는 문장을 생성하는 것뿐만 아니라 원문과 번역문 , 각 단어 간의 매핑 관계를 추가로 고려해야 합니다. 그 관계를 정렬이라고 부릅니다.

- 정렬
- 퍼틸리티퍼틸리티에 대한 확률은 p(n|w)로 정의 되고, n은 퍼틸리티 값, w는 원문의 단어 입니다. 그래서 음악은 높은 확률로 음악으로만 번역 될 것이기 때문에 p(1|music) = 0.9 된다고 합니다.
- 원문의 단어가 번역 후에 몇 개의 단어로 나타내는지를 의미합니다.
- 왜곡
- 원문의 단어가 번역문에서 존재하는 위치를 나타냅니다. 왜곡에 대한 확률은 p(t|s, l) 로 정의가 되며 t 번역문에서 각 단어의 위치, s는 원문에서 각 단어의 위치 그리고 l은 번역문의 길이입니다.
- 예문
E: Everyone(1, 2) clapped(6, 7, 8) in(4) time(5) to(·) the(·) music(3)
-> K: 모두(1) 가(2) 음악(3) 에(4) 맞춰(5) 손뼉(6) 을(7) 쳤다(8)
p(E|K) =
{p(2|Everyone) x p(1|1, 8) x p(2|1, 8) x p(모두|Everyone) x p(가|Everyone)} x
{ p(3|clapped) x p(6|2, 8) x p(7|2, 8) x p(8|2, 8) x p(손뼉|clapped) x p(을|clapped) x p(쳤다|clapped) } x
{p(1|in) x p(4|3, 8) x p(에|in)} x
{p(1|time) x p(5|4, 8) x p(맞춰|time)} x
{p(0|to) x} x
{p(0|the) x} x
{p(1|music) x p(3|7, 8) x p(음악|music)}이후에 두 단어 이상으로 정렬을 구하는 구문 기반 번역이 등장해서 2006년 까지도 사용되었습니다. 하지만 이후에 하나의 단어를 기반으로 정렬 값을 구하기 때문에 한계를 가지고 있습니다. 그래서 이후에 신경망 기계 번역이 등장합니다.
신경망 기계 번역(Neural Machine Translation)
Greedy Algorithm
신경망 기계 번역에서 우리가 주목하는 부분은 바로 단어를 결정하는 부분입니다. 모델이 예측한 predict 값을 softmax를 통해 확률 값으로 변환 후 가장 높은 확률을 갖는 단어가 다음 단어로 결정됩니다. 이 부분에서 탐욕 알고리즘이 사용되었다고 할 수 있습니다. 탐욕적인 방법으로 문장을 Decoding했다고 해서 기계 번역에서는 Greedy Decoding이라고 합니다.
Greedy 알고리즘은 미리 정한 기준에서 매 순간에 가장 좋은 확률 값을 가진 값을 선택하는 알고리즘입니다. 주로 최적화 문제를 푸는데 사용됩니다.
탐욕 알고리즘은 효율적이지만 최적의 해라는 것을 보장하지는 못합니다. 아마도 매 순간 상황에서 최적의 확률을 구하지만 모든 상황의 데이터를 고려하는 것은 아니기 때문입니다.
그렇다면 이것을 해결하기 위한 방안이 무엇이 있을까?
바로 탐욕 알고리즘의 확장 버전인 Beam search입니다.
Beam Search
모든 문장의 경우를 만들어서 최적의 해를 찾아나가는 방식으로 위의 문제를 해결해도 좋지만 그럼 시간 복잡도가 매우 커집니다. O(v^L)이 됩니다. 이는 효율성 측면에서 문제가 되기 때문에 이러한 아이디어에서 Beam search가 나왔습니다.
Beam search는 단어 사전으로 만들 수 있는 모든 문장을 만드는 대신 지금 상황에서 가장 높은 확률을 갖는 Top-k 문장만 남기는 것입니다.
상위 몇개의 문장을 볼지는 Beam size로 정의해 줍니다. Beam size와 연산량과는 성능간의 Trade off 관계를 가지고 있기 때문에 자신이 가진 자원 내에서 가장 높은 값을 가질 수록 성능은 좋아집니다.
그러나 유의할 점은 모델 입장에서는 뭐가 좋은 번역인지 알 수 없기 때문에 모델 학습 단계에서는 Beam Search를 사용하지는 않습니다.
위에서 살펴본 내용들은 모두 확률을 기준으로 단어를 선택해 왔습니다. 그런데 매번 새롭지만 의미가 유지되는 방식으로 문장을 생성할 수는 없나? 하고 고민하게 됩니다.
Sampling
그 방법 중 하나가 확률적으로 단어를 뽑는 샘플링입니다. 언어 모델은 반복적으로 다음 단어에 대한 확률 분포를 생성하기 때문에 그 확률 분포를 기반으로 랜덤하게 단어를 뽑습니다. 높은 확률을 갖는 단어를 택하는 경우가 가장 많기 때문에 랜덤이지만 가능성이 높아집니다.
하지만 실제로 서비스에는 거의 사용되지 않습니다. 대신 모델을 학습시킬 때 사용되는 경우가 있습니다. Back Translation이 그 경우입니다. Epsilon-Greedy도 자연어 처리에 강화학습을 적용한 경우에 등장하기도 합니다.
Data Augmentation
데이터 증강은 훈련 데이터를 부풀리는 기술입니다. 데이터를 부풀리는 이유는 성능을 더 좋게 만들기 위해서 입니다. VGG 모델에서 똑같은 사진을 크기를 달리해서 따로 넣어주는 것이 미묘하지만 성능이 올라갔다고 합니다.
Lexical Substitution
- 동의어 기반 대체단어 자체는 의미를 가지고 의미는 개념과 같이 계층적 구조를 가집니다. 원핫 벡터로는 그런 단어의 의미와 특징을 잘 반영할 수 없어 계층 구조를 잘 반영해서 분류하고 데이터베이스로 구축하면 자연어 처리를 할 때 매우 큰 도움이 될 것입니다.
- WordNet워드넷은 NLTK로 Wrapping되어 있어서 import해서 사용할 수 있고, 그리고 동의어 집합을 제공하기 때문에 지도 학습을 통해서 단어 중의성 해소 문제를 풀 수 있습니다.
- 한국어도 kaist와 부산대학교에서 구축해 놓은 wordnet이 있고 사전을 잘 구축해서 사용할 수 있지만 너무 큰 비용과 시간이 소요됩니다. 즉 규칙 기반 기계 번역처럼 모든 것을 사람이 정의해야 한다는 한계가 있습니다.
- 처음에는 기계 번역을 돕기 위한 목적으로 만들어졌습니다. 동의어 집합 또는 상위어나 하위어에 관한 정보가 특히 잘 구축되어 있습니다.
- 이러한 용도롤 구축된 데이터 베이스를 시소러스라고 합니다. 대표적으로 WordNet이 있습니다.
- 시소러스란 어떤 단어의 동의어나 유의어를 집중적으로 구축 해놓은 사전을 의미합니다. 동의어 기반 대체는 시소러스를 활용한 방법입니다.
- Embedding 활용 대체이 밀집된 공간 내에서 단어 간의 유사도를 구해서 가장 유사한 단어를 구할 수 있습니다
- pre -training word Embedding을 활용하는 방법이 있습니다. Word2Vec이나 Glove등이 있습니다. 학습된 Embedding은 유사한 단어들끼리 비슷한 공간에 밀집되어 있습니다.
- TF-IDF 기반 대체
- 여러 문서를 기반으로 단어마다 중요도를 부여하는 알고리즘입니다. 낮은 TF-IDF 값은 핵심 단어가 아니기 때문에 다른 단어로 대체해도 문맥이 크게 변하지는 않습니다.
단일 언어 데이터는 구하기가 쉽고 많지만 병렬 쌍을 이룬 언어 데이터는 찾기가 어렵기 때문에 이런 문제를 해결하기 위해서 등장한 것입니다.
Back Translation
Back Translation은 번역 모델에 단일 언어 데이터를 학습시키는 방법입니다.
일반적으로 기계번역 모델은 Encoder-Decoder의 구조를 이루고 Source Sentence가 Encoder에 입력되고 Target Sentence가 Decoder에 입력되어 훈련을 진행합니다. 그래서 두 문장이 한 쌍을 이루게 되는데 Back translation은 단일 데이터로만 훈련을 한다고 두가지 방법을 제안합니다.
- Dummy Source Sentence그런데 단일 데이터가 병렬 데이터의 수를 넘어가 버리면 Decoder가 Source sentence로 부터 추출한 정보를 잊어버리고 Target Sentence에 의존적인 양상을 보이게 됩니다.
- 그래서 제안된 것이 Back Translation, Synthetic Source Sentence입니다
- Encoder의 입력으로 Dummy 값을 주는 것입니다. null 토큰을 생성해서 Target sentence의 단일 데이터와 한 쌍을 이루게끔 하였습니다. 그리고 Encoder의 모든 Parameter를 Freeze해서 Dummy값에 대한 학습이 이뤄지지 않도록 하였습니다.
- Synthetic Source Sentence인공 데이터를 가지고 이 후에 구글에서 논문을 내는데 Map한 모델보다 Non Map한 모델이 더 좋은 성능을 냈다고 합니다. Non-map은 샘플링해서 높은 확률 값을 생성하는 것이고 MAP는 가장 높은 확률을 갖는 데이터를 생성하는 것입니다. 하지만 Non Map 방법이든 Map 방법이든 생성된 인공 데이터가 어떤 정보를 얼마나 포함하느냐가 중요하고, 그렇다면 가장 효과적인 최소한의 병렬 데이터 수가 무엇인지에 대해서 알아냅니다.Back Translation은 적당한 양의 병렬 데이터만 있다면 활용이 가능합니다.
- 그 결과 64만개의 병렬 데이터를 가지고 있을 때부터 효과를 보이기 시작합니다. 64만 개의 병렬 데이터만 확보된다면 500만 개가 있을 때의 성능을 유사하게 만들 수 있다는 실험 결과를 냅니다.
- null값 대신에 Target sentence를 보고 인공적인 Source Sentence를 만드는 방법론 입니다. 생성된 인공 데이터를 Synthetic Source Sentence라고 하고 인공 데이터를 생성하는 과정을 Back Translation이라고 합니다.
Random Noise Injection
문장에 노이즈를 주는 방법입니다.
- 오타 노이즈 추가
- 오타 노이즈를 추가해서 노이즈를 추가합니다
- 공백 노이즈 추가이를 마스크 언어 모델링이라고 한다. BERT나 GPT-2, XLNet이 있습니다.
- 완벽한 공백이라기 보다는 일부 단어를 공백 토큰으로 친환합니다. 학습의 과적합을 방지하는데에 좋은 효과를 볼 수 있습니다.
- 랜덤 유의어 추가
- 위에는 문장의 의미 유지하지만 랜덤 유의어 방식은 실제 노이즈를 추가합니다. 문장에서 불용어가 아닌 단어를 랜덤하게 뽑아서 해당 단어와 유사한 단어를 골라서 아무렇게나 삽입하는 방식입니다.
평가 지표
Blue Score
Bilingual Evaluation Understudy로 번역 평가 지표입니다.
데이터 X가 순서 정보를 가진 단어들로 이뤄져 있고 y 또는 단어들의 문장으로 이루어진 경우에 사용되고 번역하는 모델에서 주로 사용이 됩니다
- n-gram을 통한 순서쌍들이 얼마나 겹치는지 측정

- 문장길이에 대한 과적합 보정
- 같은 단어가 연속적으로 나올 때 과적합 되는 것을 방법
GLUE Score
기계 번역 너머의 자연어 이해를 평가하기 위해 고안된 지표입니다.
general language understanding Evaluation 벤치마크는 범용적인 자연어 이해를 개발하기 위한 목적으로 제작된 데이터 셋 입니다. Glue는 자연어 처리 모델을 훈련 시키고 그 성능을 평가 및 비교 분석하기 위한 데이터 셋들로 구성되어 있습니다.
9개의 Task 데이터 셋으로 구성된 GLUE는 모델들의 자연어 이해 능력을 평가하기 위해 고안되었으며 이제 전이 학습 모델들을 평가하기 위한 필수 벤치 마크입니다.
GLUE가 탄생하게 된 이유는 End to end로 정해진 해당 문제를 푸는데만 적합하게 훈련된 과거 모델들이 특정 테스크만 잘 해결하면 되었기 때문에 평가가 쉬웠지만 최근에는 전이 학습으로 일반화된 이해를 평가하기 ㅟ한 평가 지표가 필요해지게 됩니다. 즉 모델이 일반적인 언어 이해 능력과 Fine Tuning을 통해 특정 태스크에 얼마나 좋은 성능을 내는지 평가하고 싶어합니다.
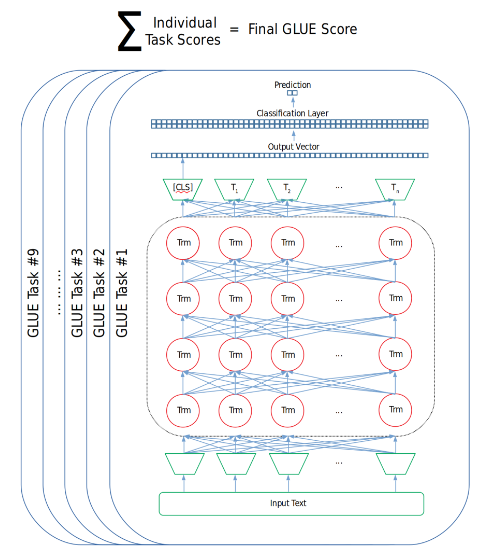
- 어떻게 활용할 수 있을까사전 훈련에 사용되었던 분류층을 제거하고 이를 GLUE 태스크를 수행하기 위한 레이어로 변경해 줍니다.
- Script for downloading data of the GLUE benchmark (gluebenchmark.com)
Reference
'AI' 카테고리의 다른 글
| SELF-ATTENTION DOES NOT NEED O(n2) MEMORY (0) | 2024.02.20 |
|---|---|
| Chatbot - 검색 기반 모델? 생성 모델? (0) | 2024.01.23 |
| Scikit-Learn Machine Learning - 머신 러닝을 알아보자 (0) | 2024.01.20 |
| Recurrent Neural Network (0) | 2024.01.20 |
| A Review of Generalized Zero-Shot Learning Methods (0) | 2024.01.16 |

