Abstract
일반적으로 self-attention은 시퀀스 길이에 비례하는 제곱수의 메모리를 필요로 한다
하지만 이 논문에서 제안하는 Attention을 대체할 수 있는 알고리즘을 통해서 시퀀스 길이에 따라 고정된 양의 메모리O(1)만 필요로 하고 더 확장하면 로그 함수에 비례하는 메모리(O(logn))만을 필요로 한다.
또한, 이 알고리즘은 메모리 효율적인 방식으로 함수를 미분하는 방법도 제공합니다
Problem
Standard Self attention

- Query
- 특정 요소에 주목해야 하는 정도를 결정
- Key
- 주목해야 할 요소
- Value
- 요소에 연관된 정보
연산 과정은 Q와 K 사이의 alignment score를 계산하고 그 score를 사용해서 value에 가중치로 사용을 한다. 가중치를 생성하는 과정에서 Softmax 거치게 된다. 이 가중치(유사도)를 value에 반영한다. 그리고 모든 값에 가중합을 통해 최종 출력을 생성한다

그런데 기존의 self attention은 시퀀스의 길이에 따라서 계산 및 메모리 복잡도가 제곱으로 증가O(n^2) 하기 때문에 긴 시퀀스의 경우에는 많은 계산 능력과 메모리가 필요하다
입력 시퀀스의 각 요소가 다른 모든 요소와 비교하게 되는데 예를 들어, 길이가 n인 입력 시퀀스가 있는 경우 첫 번째 요소에 대한 n 비교, 두 번째 요소에 대한 n 비교 등이 발생하여 총 n * n(또는 n^2) 비교가 발생한다. 즉 alignment score를 계산하고 n^2차원의 행렬에 저장이 된다. 그렇기 때문에 n^2의 저장 공간을 필요로 하게 된다.
그리고 다시 이 값을 다시 가중 합으로 합산하는 과정으로 다시 n^2 연산을 하게 된다.
Solution
기존의 self-attention의 문제를 해결하기 위해 저자들은 메모리 사용량을 크기 줄이면서 효율적으로 계산할 수 있는 새로운 알고리즘을 제안한다.
Algorithm

Softmax를 계산하는 과정에서 지수 함수의 합으로 나누는 계산을 마지막으로 미룸으로써 메모리 사용량을 줄인다. (lazy softmax)
기존의 연구와 중복이 되는 부분이 있지만 다른 점은 메모리 복잡성에 대한 내용은 이전 연구에서 다루지 않는다
이 알고리즘에서 memory overhead는 d 차원의 벡터 v, 스칼라 s 로 이루어져 있다.
- 벡터와 스칼라를 overhead memory에 0으로 초기화한다. 여기서 v는 각 가중치를 계산하는 과정에서 사용되는 중간 값들이 저장되고 , 스칼라는 가중치를 정규화 하는데 사용되는 합계를 저장한다
- Q와 K 사이에 alignment score를 계산해서 벡터에 더한다. 동시에 score의 지수함수 값를 계산해서 스칼라에 더함으로써, 모든 score에 지수의 합을 계산한다
- 모든 Value 값에 대한 연산이 끝나고 스칼라로 나눠서 최종 결과를 얻는다
입력이 특정 순서로 제공된다고 가정하는데 모든 쿼리에 대한 결과를 순차적으로 계산하고 메모리 복잡성은 O(logn)이 된다.
Numerical Stability
Softmax 함수에서 수치적 안정성은 중요한 문제가 될 수 있다
softmax 함수는 유사도를 지수화 하는데 너무 커지면 결과가 무한대로 갈 수 있다.
이 문제를 해결하기 위해 maximum score 를 추적하는 추가적인 스칼라를 도입한다. 스칼라는 지수화된 score 합을 나눠줄 때 사용된다.
maximum score를 기록해 놓고 모든 score에서 이 maximum score를 빼서 지수화 하고, 나중에 다시 정규화를 한다.
이런 과정을 통해 무한대로 발산하는 것을 막을 수 있다.
- v벡터와 스칼라s를 0으로 초기화 하고 maximum score에 해당하는 m을 -inf로 초기화 한다
- k, v 의 쌍이 주어지기 전에 score를 계산 한다. m을 계산하기 위해서 계산한 score 사이에서 최대값을 찾는다.
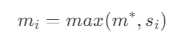
- $$ m_i = max(m^*,s_i) $$
- 벡터를 업데이트 하기 위해서 벡터에서 m을 빼주고 지수화 하고 더해준고 스칼라 s에도 지수화 해서 더해준다.

JAX
JAX를 사용해서 TPU에서 효율적으로 실행한다
계산 부분을 여러 개의 부분으로 나눠서 처리함으로써 병렬 처리를 하게 된다. 추가적인 메모리를 필요로 하지만 더 큰 계산을 관리할 수 있는 작은 청크로 나눠서 처리하면서 메모리 사용을 최적화하고 계산 효율을 높였다.
쿼리를 일정한 크기의 청크로 자르고 이 청크를 순차적으로 처리하게 된다. 키와 값에 대한 청크 크기는 시퀀스 길이의 제곱근으로 설정된다. 따라서 시퀀스 길이가 길어지면 청크의 크기도 증가한다. 수치적 안정성을 위한 연산이 수행되고 최종 출력이 생성된다
입력 데이터를 청크(chunk)로 나누고, 각 청크에 대해 어텐션을 개별적으로 계산한다. 이는 전체 입력에 대해 한 번에 계산을 수행하는 대신, 작은 부분에 대해서만 계산을 수행하여 메모리 사용량을 대폭 줄일 수 있다
**jax.lax.dynamic_slice**와 **jax.lax.dynamic_update_slice**를 사용하여 필요한 부분만 메모리에 로드한다. 이는 모든 키(key)와 값(value) 벡터를 메모리에 저장하지 않고, 필요한 부분만 접근하여 메모리 사용을 최적화한다
키 크기만큼 반복적으로 계산해야 하는 부분을 jax.lax.map 함수를 사용하여 병렬적으로 처리한다. 이렇게 하면 메모리 사용량을 최적화할 수 있다.
각 청크에 대해 최대값을 계산한 후, 이를 전역 최대값으로 사용하여 각 청크의 소프트맥스 정규화를 안정화시킨다. 이 방법은 각 청크가 서로 다른 스케일로 정규화되는 것을 방지한다
코드에서는 jax 라이브러리의 특정 함수를 사용하여, 계산 그래프를 효율적으로 관리하고 메모리를 절약한다 예를 들어, exp, stop_gradient 등의 연산은 자동 미분 계산에서 불필요한 중간값을 저장하지 않도록 최적화되어 있다
각 청크에 대해 계산된 어텐션을 요약함으로써, 전체적인 계산에 필요한 정보만을 유지한다.
jax.lax.cond 함수와 같은 함수를 사용하여 메모리 할당을 최적화하고 불필요한 메모리 사용을 줄일 수 있
Result
모든 연산은 single TPUv3 칩에서 이루어졌고 TPUs에서 메모리 오버 헤드도 측정했다. 이 실험을 위해서 하나의 attention head를 사용했다
이 알고리즘은 메모리 병목 현상을 해결하고 최소 백만 시퀀스 길이에서 확장이 된다. 이 길이에서 알고리즘이 1조 이상의 Q,K 조합을 처리할 수 이는 크기로 확장이 가능하다. (시간 복잡도는 여전히 제곱에 비례한다) 이는 self- attention 연산 자체를 단독으로 분석했으므로 실제 큰 연산 모델에서의 연산 성능은 다를 수 있다고 말한다.
OOM(Out of memory) 부분에서도 표준 attention에서 발생했지만 이 알고리즘을 적용하면 발생하지 않았다.
새로운 알고리즘은 기존의 self attention과 똑같은 결과이지만 훨씬 적은 메모리를 사용한다.

연구에서 알고리즘은 K 와 Q를 모두 청크로 나눈다. 이전 연구에서 쿼리만 청크로 나누는 것은 계산 속도를 느리게 한다고 알려져 있다. 다양한 청크 크기를 사용해서 런타임을 비교한 것을 보면 작은 청크 크기에서는 별로 좋지 않지만 큰 청크 크기에서는 효과를 볼 수 있다. . 즉 청크 크기가 작을 수록 비실용적이다.
이 연구에서는 키를 청크로 나눔으로써 추가 메모리를 절약할 수 있다. 표준 attention같은 경우에는 쿼리를 청크로 나눠서 하는 경우 성능을 최대화 하기 위해서 시퀀스 64이하로 줄여야 이득이 최대화된다. 하지만 시퀀스 길이가 증가하면 쿼리 청킹은 결국 속도 저하를 만들게 된다
하지만 메모리 효율적인 attention 알고리즘은 큰 청크 크기여도 느려짐이 없다. 메모리가 제한적인 상황이라면 효율적인 attention 알고리즘이 쿼리 청킹의 이득을 극대화할 수 있다.
Conclusion
메모리는 절약했으나 self attention에 대해서 o(n2)의 시간 복잡도를 갖는다. 또 단일 쿼리 attention 같은 경우에는 o(n)의 시간 복잡도가 필요하다
그렇지만 간단한 트릭으로 메모리 효율적으로 사용할 수 있었고 이 연구를 통해서 어텐션이 본질적으로 메모리를 많이 사용하지 않는다는 것을 많이 인식하여 새롭게 아키텍처를 바라볼 수 있는 계기가 되었으면 한다
Reference
https://arxiv.org/pdf/2111.00396.pdf
'AI' 카테고리의 다른 글
| Chatbot - 검색 기반 모델? 생성 모델? (0) | 2024.01.23 |
|---|---|
| 번역의 흐름 (0) | 2024.01.22 |
| Scikit-Learn Machine Learning - 머신 러닝을 알아보자 (0) | 2024.01.20 |
| Recurrent Neural Network (0) | 2024.01.20 |
| A Review of Generalized Zero-Shot Learning Methods (0) | 2024.01.16 |

